

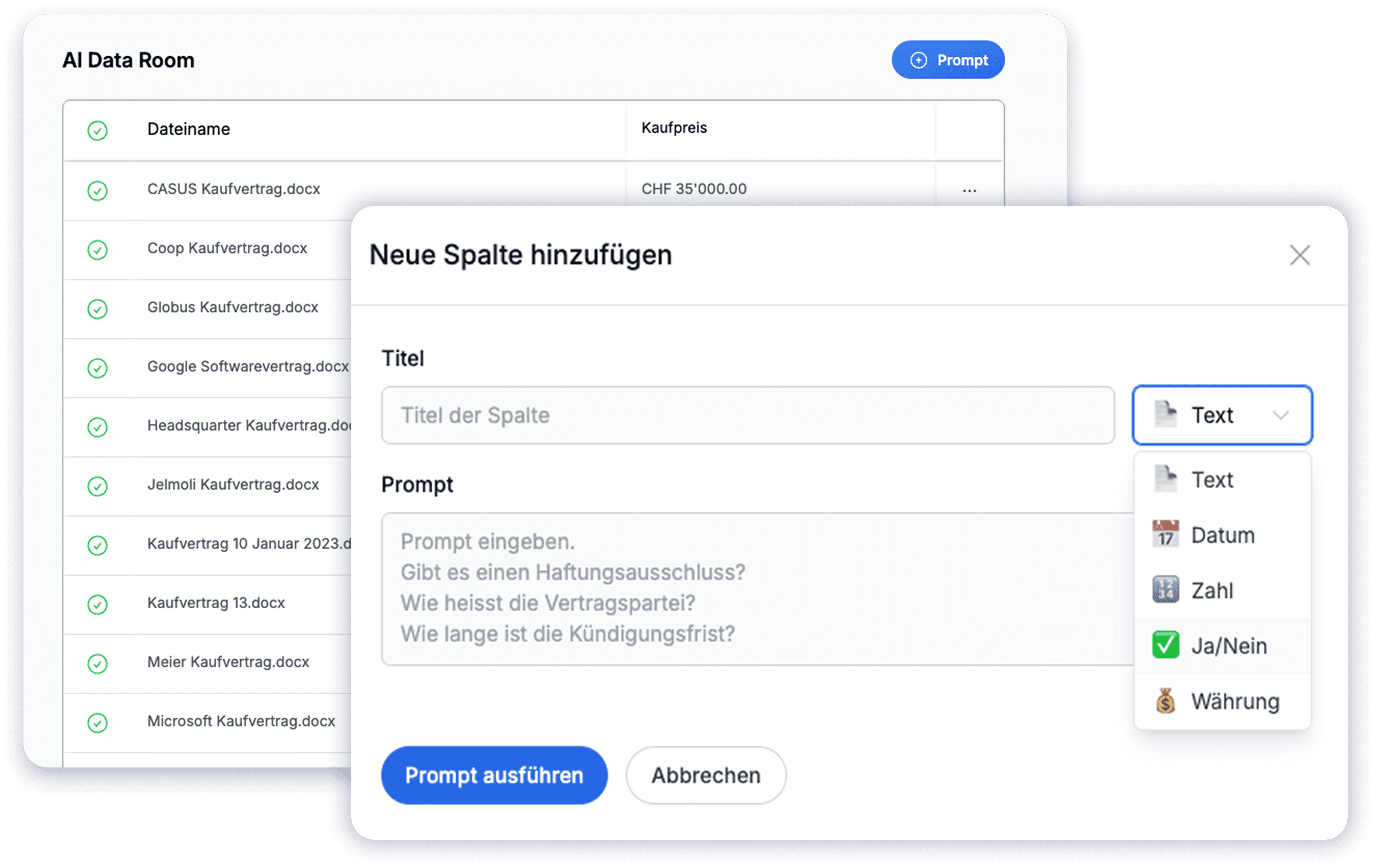
Faster due diligence with a clause matrix
Anyone who has ever supported a due diligence process or a larger data room review knows the pattern: hundreds of documents, tight deadlines – and in the end, it often comes down not to “how much” you read, but how quickly you identify the critical points, compare them, and document them clearly.
That’s exactly where the CASUS AI Data Room comes in: it helps you extract key clauses across many documents, make deviations visible, and at the same time detect personal data in the data room.
Why AI data rooms are especially relevant right now
Data rooms are no longer just an M&A topic. Vendor onboarding, outsourcing, IP transfers, joint ventures, or large master agreements often create data-room-like situations today: many documents, many variants, many risks.
The bottleneck is rarely missing expertise – it’s time and consistency:
Where are the contractual risks actually distributed?
Which documents deviate from the standard?
Which termination models exist in parallel?
Which personal data is hidden in the data room without anyone noticing?
With an AI-driven approach, the data room shifts from document storage to a searchable, comparable landscape of risks and clauses.
Use case 1: Extract and compare key clauses across many documents
The biggest lever is usually not the individual document – it’s the comparison across all documents. CASUS automatically identifies key clauses (e.g., liability, IP, SLAs, termination) and presents them in a structured way. This helps you see faster where you need to take a closer look.
Typical day-to-day outputs:
Clause matrix: key topics extracted per document (liability, IP, SLAs, termination, etc.)
Deviations and red flags: highlighted and prioritized (e.g., liability without a cap, termination notice period > 12 months)
Consistency checks across the data room: e.g., comparing termination models, liability logic, or SLA standards across all files
Instead of fighting through every version one by one, you get clarity sooner: which documents are “clean,” which are outliers – and which are true dealbreakers?
Use case 2: Detect personal data and share in line with FADP and GDPR
Data rooms often contain more personal data than people expect – not just obvious items (names, emails), but also hidden or sensitive content (e.g., HR data, ID numbers, bank details, health references).
CASUS helps you find and prioritize such data across the entire data room so you can safely share or prepare documents.
What’s especially useful:
Identification of personal data across all documents (e.g., names, emails, phone numbers, addresses, IDs)
Prioritization of sensitive data (e.g., HR and health data, ID and bank details)
A clean anonymization process: so your team can clearly document what was changed and why
Especially in Switzerland (FADP) and in DACH setups with GDPR relevance, this isn’t just “nice to have” – it can become a real compliance blocker if it’s discovered too late.
What improves in practice
An AI data room delivers three practical effects you can feel immediately:
Speed: You move faster from “reading documents” to “spotting risks.”
Comparability: You see deviations across all documents – not just isolated cases.
Confidence when sharing: Personal data becomes visible before anything is sent externally.
And importantly: this doesn’t just relieve Legal. M&A, procurement, compliance, and management also benefit because results become more structured, prioritized, and easier to communicate.
Conclusion
The CASUS AI Data Room makes data room reviews more efficient by extracting key clauses across many documents, making them comparable, and prioritizing deviations. At the same time, it helps detect personal data and share content in line with FADP and GDPR. The result: “lots of material” turns into a clear risk map faster – and review stress becomes a repeatable process.
FAQ
In which situations is an AI data room most worthwhile?
Due diligence (M&A), vendor and supplier reviews, outsourcing, large contract migrations, master agreements with many annexes – anywhere many documents need to be reviewed and compared consistently.
What’s the difference vs. normal full-text search in a data room?
Full-text search finds words. An AI data room extracts and structures clauses by topic and makes deviations and risks visible across multiple documents.
Does this replace the legal review of individual documents?
No. It accelerates orientation, prioritization, and comparability – legal assessment and decision-making remain with the lawyers.
How does it help with FADP and GDPR in concrete terms?
By identifying and prioritizing personal (and sensitive) data across all documents, so you can prepare and document sharing and anonymization cleanly.





